Aktualizacja: Niedługo nacieszyliśmy się dostępem do Fable 5 (wielu z nas zapewne w ogóle nie zdążyło z niego skorzystać). W piątek wieczorem polskiego czasu Anthropic poinformował, że musiał wyłączyć dostęp do Fable 5 dla wszystkich klientów, bo rząd USA zażądał, by dostępu nie mieli do niego żadni nie-Amerykanie, łącznie z pracownikami Anthropica i obcokrajowcami pracującymi w USA.
Tak naprawdę wiedzieliśmy, że Fable nadchodzi. Bo Fable (bajka) to tak naprawdę brat bliźniak Mythosa (mitu), modelu, którego pojawienie się w kwietniu tego roku wywołało wyprzedaż akcji firm software’owych i związanych z cyberbezpieczeństwem. Bo był tak dobry w wykrywaniu dziur bezpieczeństwa w oprogramowaniu i systemach informatycznych.
W mediach pojawiły się alarmistyczne artykuły, i to pomimo tego, że Anthropic dał dostęp do modelu tylko wybranym partnerom w ramach projektu Glassdoor. Ale było oczywiste, że Anthropic nie tworzył modelu dla wąskiej grupy klientów, nawet jeśli klienci nieźle płacili (i ustawili się w długiej kolejce do modelu). I teraz dostajemy Mythosa wszyscy – pod nieco mniej groźnie brzmiącą nazwą. Bo Fable to Mythos z zabezpieczeniami. Takimi, żeby model nie był wykorzystywany w niecnych celach.
Claude Fable 5 – gdzie błyszczy…
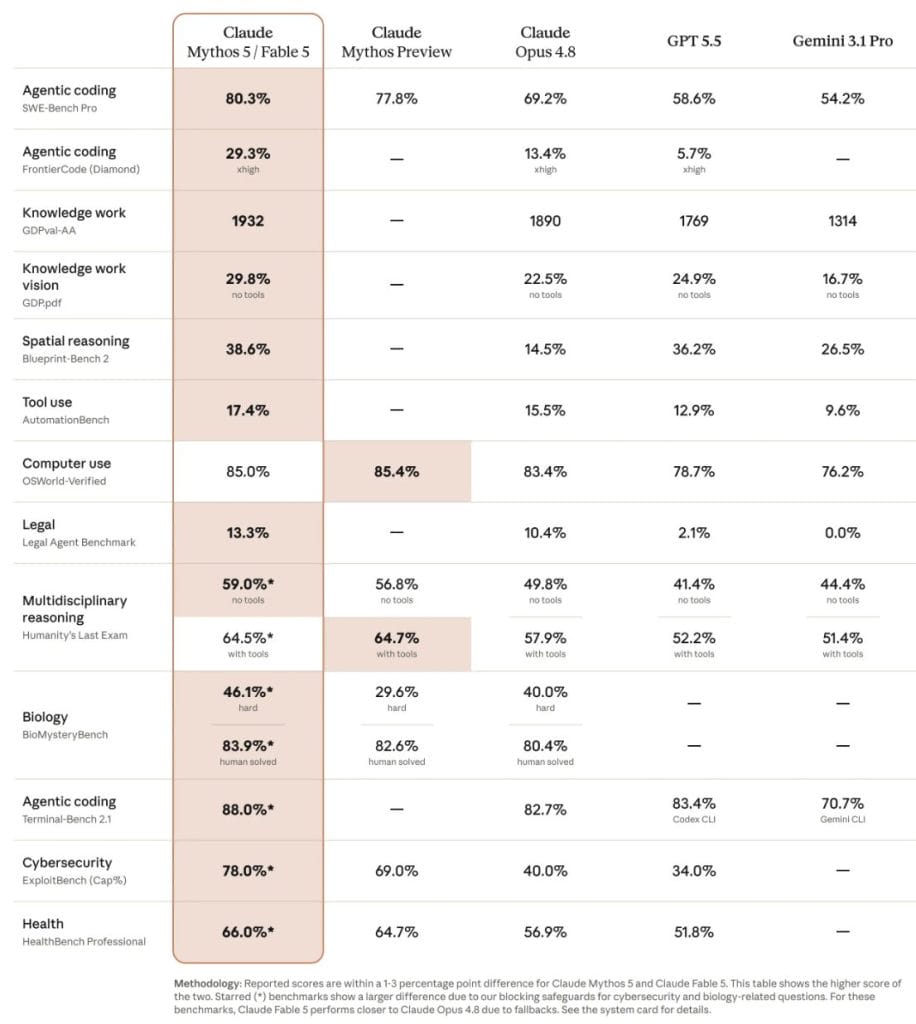
Czy faktycznie Fable ma aż tak wielką przewagę w osiągach nad konkurencją? W kategoriach najważniejszych dla Anthropica, a więc tych związanych z inżynierią oprogramowania, na pewno tak. Pod względem agentowego programowania odleciał konkurencji, osiągając 80.3% w SWE Bench Pro (GPT-5.5, najlepszy produkt konkurencji, ma raptem 58.6%), a w podobnym benchmarku Terminal Bench 2.1, gdzie ostatnio najlepszy był GPT-5.5, wyraźnie wyprzedził konkurencję.
Dobrze jest również pod względem rozumowania naukowego – w benchmarku Humanity Last Exam, Fable bez użycia narzędzi (na przykład Pythona czy wyszukiwania internetowego) ma sporo lepszy wynik niż GPT-5.5 z narzędziami.
Anthropic chwali zwłaszcza umiejętności modelu w zakresie długich i bardziej złożonych zadań. Im dłuższe i bardziej skomplikowane zadanie, tym większa przewaga Fable nad konkurencją. A więc powinien błyszczeć przede wszystkich w takich dziedzinach, jak inżynieria oprogramowania, analityka i badania naukowe.
… a gdzie jest tylko dobry?
Jeśli spojrzymy na tabelkę od Anthropica, to można by odnieś wrażenie, że jego najnowszy model jest najlepszy w każdej kategorii. Czasami z wielką przewagą, czasem tylko trochę, ale najlepszy pod każdym względem.
Laby AI już nas przyzwyczaiły, że prezentują głównie te benchmarki, w których wypadają co najmniej nieźle, skrzętnie pomijając te mniej korzystne. Tu z pomocą przychodzi nam Artificial Analytics, niezależna firma analizująca umiejętności modeli AI, częściowo korzystająca z zewnętrznych benchmarków, częściowo wykorzystująca własne.
W rankingu Artificial Analytics Fable również wygrywa wyraźnie, ale szczegóły są już nieco bardziej zniuansowane. Wynik ogólny (AA Intelligence Index) to 65, wyraźnie ponad 61 pkt. dla Claude Opus 4.8 i 60 dla GPT-5.5. Przewaga w benchmarku AA-Omniscience, mierzącym wiedzę i odporność na halucynację jest jeszcze większa – tu Fable uzyskał 40 pkt wobec 33 dla najbliższej konkurencji (Gemini 3.1 Pro).
Są jednak pod-benchmarki, w których to nie Fable przewodzi stawce. Mimo tego, że Anthropic twierdzi, że Fable świetnie nadaje się do zadań o długim czasie trwania, to w benchmarku AA-LCR, mierzącym rozumowanie przy długim kontekście, Fable tak naprawdę wypadł gorzej od najlepszych modeli OpenAI i Google. Jeszcze gorzej jest w benchmarku IFBench mierzącym to, jak ściśle modele stosują się do otrzymanych instrukcji. Tutaj Fable uzyskał raptem 63 pkt wobec 76 pkt dla GPT-5.5 i 77 dla Gemini 3.1 Pro.
Czym się różni Fable od Mythosa?
A czym różni się Fable od osławionego Mythosa? De facto tylko zabezpieczeniami, tzw. guardrails, które określają, co modelowi wolno, a czego nie wolno robić. Konkretnie – każde zapytanie (prompt) kierowane do modelu przechodzi przez osobny system AI zwany klasyfikatorem. Jeśli klasyfikator wykryje potencjalnie złośliwe użycie, zwłaszcza w dziedzinie cyberbezpieczeństwa, biologii i chemii lub próbę „destylacji” modelu (czyli użycia go do trenowania innych, konkurencyjnych modeli), to przekierowuje takie zapytanie do mniej potężnego modelu Opus 4.8.
Sam Mythos doczekał się nowej wersji. O ile dotychczas był dostępny jako Preview, to teraz uzyskał status pełnej wersji jako Claude Mythos 5. Nadal będzie dostępny tylko dla niektórych partnerów poprzez projekt Glasswing, gdzie z jego możliwości mogą skorzystać podmioty odpowiedzialne za cyberobronę i dostawcy infrastruktury krytycznej. Ta wersja Mythosa będzie miała zniesione zabezpieczenia w zakresie cyberbezpieczeństwa. Z kolei wersja pozbawiona zabezpieczeń w dziedzinie biologii i chemii zostanie niedługo udostępniona wybrany badaczom w dziedzinie nauk biologicznych.
Claude Fable 5 – kto może skorzystać?
Dla kogo dostępny jest Claude Fable 5? Przede wszystkim dla użytkowników płatnych planów Claude, od Claude Pro w górę, ale… tylko na chwilę. Anthropic najwyraźniej chce zaostrzyć apetyt klientów na nowy model i udostępnia go wszystkim swoim płacącym klientom w ramach planów abonamentowych do 22 czerwca. Po tej dacie Fable przez jakiś czas będzie dostępny tylko przez API. Czemu? Bo model jest duży i zasobożerny, a firma spodziewa się eksplozji popytu na jego umiejętności, co może solidnie przeciążyć dostępną firmie infrastrukturę obliczeniową. W przyszłości dostęp do modelu w planach subskrypcyjnych ma zostać przywrócony – ale tutaj Anthropic nie podaje już żadnych konkretnych dat.
Model jest i będzie dostępny dla każdego poprzez tak zwane API – ale z tej możliwości skorzystają przede wszystkim programiści oraz firmy, które postanowią uczynić z Fable podstawę własnego produktu.
Claude Fable 5 – ile kosztuje?
Dostęp do modelu Fable dla subskrybentów jest w pewnym sensie bezpłatny – ale tylko w pewnym sensie. Do każdego planu subskrypcyjnego przypisane są limity użycia – i krótkookresowe, około 5-godzinne i tygodniowe. Po ich osiągnięciu Claude po prostu przestaje odpowiadać (chyba że wybierzecie opcję „pay-as-you-go”). A Fable… zużywa limity dwa razy szybciej niż już i tak „limitożerny” Opus. Efektywnie, Fable jest więc dwa razy droższy od swojego nieco mniej zdolnego brata.
Taka sama jest proporcja, jeśli chodzi o dostęp do API. Korzystanie z Claude Fable 5 sporo kosztuje – to 10 dolarów za milion tokenów wejściowych i 50 dolarów za milion wyjściowych. To dwa razy więcej niż dla modelu Opus i ponad trzykrotnie więcej niż dla Sonnet. Biorąc pod uwagę, że używanie Fable ma sens głównie przy bardzo złożonych zadaniach, przy których zużywanych jest wiele tokenów, to koszty użycia Fable na pewno będą wysokie. Ostatnio Uber narzekał, że roczny budżet na AI przepalił w cztery miesiące. Korzystając z Fable pewnie zrobiłby to w czasie jeszcze krótszym.
Dla kogo?
Fable 5 ma największy sens dla osób, których praca polega na długich, wieloetapowych zadaniach – programistów pracujących nad rozbudowanymi projektami, analityków przetwarzających duże ilości dokumentów, badaczy syntetyzujących wiedzę z wielu źródeł, a także wszystkich, którzy regularnie zlecają AI zadania trwające nie minuty, lecz godziny. Jeśli często łapiecie się na tym, że AI „gubi wątek” w połowie złożonego zadania, nie radzi sobie z długim dokumentem albo potrzebuje ciągłego nadzoru i korygowania — Fable 5 jest modelem, który powstał właśnie z myślą o Was.
Różnica w stosunku do poprzednich modeli jest najbardziej odczuwalna nie przy prostych pytaniach, lecz właśnie wtedy, gdy zadanie jest naprawdę trudne. Ponadto, jak pisze Matt Berman, który miał okazję przetestować model przed premierą, Fable jest po prostu wolny. Więc odpowiedzi na proste pytania będę tylko niewiele lepsze, a dużo wolniej generowane.
Jeśli używasz AI głównie do pisania maili, streszczania artykułów, generowania pomysłów czy szybkich odpowiedzi na pytania — spokojnie możesz zostać przy Claude Sonnet lub nawet Haiku. Fable 5 jest droższy w użyciu i szybciej wyczerpuje limity planu, więc płacenie za jego możliwości przy lekkich zadaniach to trochę jak wożenie codziennych zakupów bolidem F1. Dla większości z nas rozsądną strategią będzie korzystanie z Fable 5 selektywnie — do najtrudniejszych zadań — a przy codziennej rutynie pozostanie przy szybszym i bardziej oszczędnym modelu.
Źródło zdjęcia: Adam Winger/Unsplash




 0 komentarzy
0 komentarzy