Jesteście zmęczeni kompletną nieznajomością przez chatboty najnowszych (a nawet tych dość już odległych) wydarzeń? Ja, jako dziennikarz, na pewno tak, bo istotnie to zmniejsza użyteczność tych narzędzi w mojej pracy. Umowa OpenAI z Axel Springer ma szanse to zmienić.
Właściciel ChatGPT, wkrótce po wygrzebaniu się z wewnętrznych problemów podpisał umowę z wydawcą gazet i portali, firmą Axel Springer, dotyczącą wykorzystywania treści newsowych wydawcy przez modele językowe będące podstawą działania chatbota.
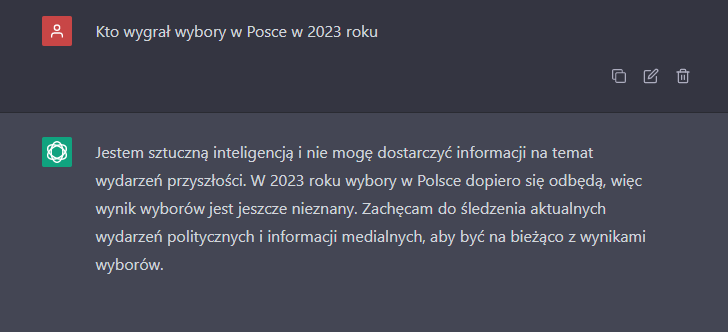
Skąd biorą się te problemy narzędzi opartych na dużych modelach językowych (LLM), takich jak chatboty ChatGPT i Bard, z wydarzeniami bieżącymi? Wytrenowanie dużych modeli językowych trwa wiele tygodni, a w przypadku największych wręcz wiele miesięcy. To sprawia, że model w momencie zakończenia treningu nie jest świadom najnowszych wiadomości. Nawet po ostatniej aktualizacji, GPT 3.5, czyli model używany przez darmową wersję ChatGPT, ma tzw. cut-off date, czyli „datę odcięcia”: styczeń 2022 r. To znaczy, że ta sztuczna inteligencja nie wie o niczym, co zdarzyło się po tym terminie.
Umowa OpenAI z Axel Springer pozwoli zaoferować użytkownikom ChatGPT streszczenia wybranych wiadomości z całego świata wyprodukowanych przez media Axela Springera, nawet tych do których dostęp jest co do zasady płatny, wraz z linkami do oryginalnych treści. Do niemieckiego wydawcy należą zarówno publikacje internetowych jak i tradycyjne takie jak Business Insider, Politico, Welt i Bild. W Polsce do Axela Springera należy Onet, Fakt czy Newsweek Polska.
Jednak prawdopodobnie to nie za tą funkcjonalność OpenAI zgodził się zapłacić, jak donosi Financial Times, dziesiątki milionów euro rocznie. Umiejętności dużych modeli językowych w zakresie streszczania dokumentów czy artykułów są powszechnie znane i nikogo nie powalą już na kolana. O wiele istotniejsza jest możliwość wykorzystywania treści Axela Springera do trenowania swoich modeli językowych. Dzięki temu chatboty będą mogły odpowiadać na pytania użytkowników o nieodległą przeszłość.
To nie pierwsza umowa dotycząca dostępu do treści dziennikarskich podpisana przez OpenAI, ale zapewne największa. Firma wcześnie zawarła porozumienia z Associated Press i American Journalism Project – ta pierwsza oferowała OpenAI dostąp do archiwów AP w zamian za dostęp do technologii generatywnej sztucznej inteligencji (GenAI), ale jej wartość gotówkowa nie jest znana; ta druga opiewała na 10 milionów dolarów, pół na pół w gotówce i w dostępie do infrastruktury.
Na polu dużych modeli językowych oferujących najnowsze wiadomości, ChatGPT będzie maił już jednak konkurenta. xAI, firma Elona Muska rozwijająca sztuczną inteligencję, również usiłuje dostarczyć najnowsze treści poprzez trenowanie modelu dla swojego chatbota Grok na bieżących tweetach – Musk jest również właścicielem portalu X (dawniej Twitter). Grok został udostępniony subskrybentom planu X Pro na początku grudnia 2023 r.
Czy nowa funkcjonalność obejmie wiadomości o Polsce? Chwilowo trudno spekulować. Nie wiemy, czy umowa obejmuje wyżej wspomniane polskie aktywa Axel Springera (a ja osobiście w to wątpię) i nie wiemy też co OpenAI miał na myśli pisząc o „wybranych” wiadomościach ze świata. Z całą pewnością artykułów o Polsce, szczególnie w Politico, ale i w Welt, jest niemało. Więc treści te być może się pokażą w ChatGPT, ale pewnie z europejskiej (Politico) lub niemieckiej (Welt) perspektywy.
Chcesz dowiedzieć się więcej o stronniczości algorytmów? Przeczytaj: Kompetencje algorytmiczne – kluczowe kompetencje XXI wieku?
Na wiadomości o Polsce z polskiej perspektywy pewnie poczekamy o wiele dłużej. Choć jak już pisaliśmy, pierwsze polskie modele językowe z prawdziwego zdarzenia pojawią się zapewne w połowie 2024 roku, ale będą one budowane bardziej pod kątem językowym niż budowania bazy wiedzy. Te większe modele obejmujące reprezentację wiedzy pojawią się później, ale nawet one mogą nie obejmować najnowszych wiadomości – konsorcjum polskich instytucji naukowych może być nie stać na kosztowną umowę z mediami.
Źródło zdjęcia: Roman Kraft/Unsplash




 0 komentarzy
0 komentarzy