Kiedy w grudniu zeszłego roku ukazała się pierwotna wersja DeepSeek-V3, świat AI w dużej mierze ją przegapił. Jednym z nielicznych wyjątków był Andrej Karpathy, jeden ze współzałożycieli OpenAI i jeden z najlepszych edukatorów świata AI. W tamtym czasie odnotował on, że V3 był trenowany na 11x mniejszej mocy obliczeniowej niż Llama 3.1 405 B a wydaje się być lepszym modelem.
Miesiąc później ukazał się „rozumujący” DeepSeek-R1, porównywalny z o1 od OpenAI, a wytrenowany po o wiele niższym koszcie i świat zamarł w zdumieniu. Okazało się, że chiński startup dysponujący starymi kartami GPU Nvidii może stworzyć model porównywalny z najlepszymi modelami amerykańskimi.
Nowy, lepszy DeepSeek-V3
A teraz mamy nowy, lepszy DeepSeek-V3-0324. Choć jest on, jak wskazuje nazwa, tylko iteracyjnie ulepszoną wersją modelu z grudnia, to podobno jego osiągi są znacznie lepsze. Podobno, bo żadnych opisów ani benchmarków od DeepSeeka nie dostaliśmy. Chiński lab AI po prostu wrzucił model do serwisu Hugging Face. To co wiemy to tyle, że model ten nadal jest dostępny na bardzo liberalnej licencji MIT.
Nieco więcej informacji dostaliśmy od badacza i komentatora AI, publikującego na platformie X pod nickiem Xeophon. Według jego testów, nowy DeepSeek jest lepszy od modelu Claude Sonnet-3.5, do niedawna uważanego za najlepszy „nierozumujący” model językowy.
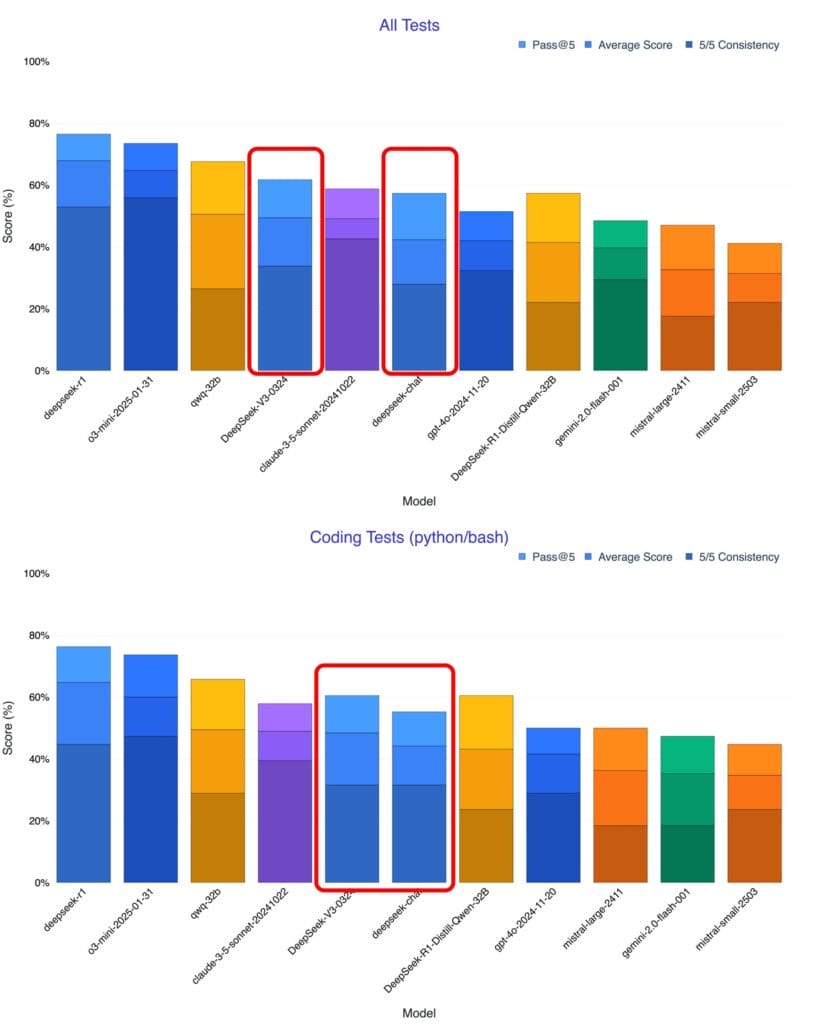
Nie wiemy, jak chiński model porównuje się z GPT-4.5, najnowszym dzieckiem OpenAI, ale musimy pamiętać, że to jednak inna liga. DeepSeek-V3 jest niemal 3 razy mniejszy niż GPT-4, a niedawne słowa Sama Altmana, że GPT-4.5 to „wielki i wolny” model sugerują, że jest on sporo większy niż GPT-4.
Nie mamy tu również porównania z modelem Claude 3.7 Sonnet – pierwszym hybrydowym systemem dostępnym na rynku. Hybrydowym, bo model sam wybiera, na podstawie zapytania, czy odpowiedzieć użytkownikowi w trybie tradycyjnym czy rozumującym, bo model może działać w każdym z tych dwóch trybów.
Niestety, jak twierdzi Xeophon, model Anthropica generował zbyt wiele błędów, by przeprowadzić na nim benchmark w sensownym czasie. To może sugerować, że Anthropic, nie chcąc zostać w tyle za OpenAI i DeepSeekiem po prostu wypuścił nie do końca dopracowany produkt.
Warto jeszcze poruszyć jeden aspekt. DeepSeek-V3 ma szansę stać się pierwszym z czołowych modeli AI w ostatnich latach, który można uruchomić na sprzęcie, który, przy pewnej dozie wyobraźni, można określić jako konsumencki. Jednemu z badaczy udało się uruchomić skwantyzowaną wersję DeepSeeka na komputerze Mac Studio. Nie jest to może komputer, który znajdziemy w każdym domu – raczej kosztująca niemal 10 tysięcy dolarów bestia z procesorem M3 Ultra i 512 GB pamięci RAM. Jest to jednak sprzęt biurkowy a nie serwerowy i pochłania 200 W energii, a nie kilka tysięcy wat, jak klastry kard Nvidii potrzebne do uruchomienia innych czołowych modeli.
Szczególnie ciekawe może się wiec stać połączenie DeepSeeka z nadchodzącym DGX Station od Nvidii. DeepSeek na własnym biurku bez wścibstwa KPCh to może być interesująca opcja. Choć pewnie jeszcze droższa niż Mac Studio.
Nadchodzi rozumujący R2. Kłopot dla OpenAI, Google i Anthropica?
O ile sam DeepSeek-V3 jest interesującym modelem, o tyle wyobraźnię porusza zapewne przede wszystkim możliwość zbudowania na nim kolejnego, lepszego modelu rozumującego. Przypomnijmy, model DeepSeek-R1, który wywołał takie poruszenie w świecie AI i na rynkach finansowych, był oparty na poprzedniej wersji modelu V3. Jeśli teraz mamy lepszy V3, to za chwilę powinniśmy dostać lepszy R1 lub wręcz R2.
I takie pogłoski pojawiają się na mediach społecznościowych. Jeden użytkownik Reddit napisał, że według plotek R2 nadejdzie w kwietniu – czyli około miesiąca po nowej wersji V3, powtarzając wzorzec z przełomu roku. Z kolei jeden z użytkowników platformy X napisał, że R2 podobno osiągnął 90% na ARC AGI – benchmarku w którym najmocniejsza wersja o3 uzyskała 88%. Przy bardzo wysokim koszcie mocy obliczeniowych.
To oczywiście niezbyt dobre wieści dla komercyjnych modeli. Jak pisałem powyżej, Anthropic wydaje się mieć problemy z modelem 3.7 Sonnet, OpenAI wypuści również hybrydowe GPT-5 dopiero w maju a Google jakoś nie może się przebić do świadomości szerszej publiki ze swoim Gemini 2.0 Flash Thinking. Dla nich pojawienie się darmowego, szybkiego i zdolnego DeepSeek-R1 to spory problem. Tym bardziej, że każda firma będzie sobie go mogła uruchomić w chmurze i uniknąć wścibstwa chińskich towarzyszy. Nie każdemu aż tak bardzo przeszkadza, że model nie powie mu prawdy o masakrze na Tiananmen.
Grafika: Zrzut ekranu ze strony DeepSeek




 0 komentarzy
0 komentarzy